Troubleshooting Services
Services are the core of a Liferay Cloud environment. This article covers troubleshooting techniques that can be used to investigate and address issues that may arise with Liferay Cloud services.
A Service is Continually Restarting
Services repeatedly restarting may signal an issue with the liveness or readiness probes for that service. When this happens, you may notice it in the General tab of the Activities panel, on the Overview for one environment.
Services that are continuously restarting due to a recurring liveness probe failure, may not complete start up before the liveness probe triggers a restart. If there is a readiness probe failure, then the readiness probe has failed to get the appropriate response a number of times in a row (possibly after the service has already fully started).
To diagnose a service that is continually restarting, we recommend the following steps:
- Check Service Logs for Liveness or Readiness Probe Failures
- Review Probe Configurations
- Review Service Logs for Startup Errors
- Adjust Probe Configurations
Check Service Logs for Liveness or Readiness Probe Failures
Navigate to the service’s page to see the logs on the first tab. Scan the recent logs to find any that indicate a probe failure.
For example, a liveness probe failure message may look like:
Liveness probe failed: HTTP probe failed with statuscode: 500
Review Probe Configurations
If you have customized your probe configurations for your environment, then it is possible that incorrect probe configuration causes the probe failures. To rule this out as the cause of probe failures, check the configurations of your liveness and readiness probes and make sure they match your environment.
Navigate to the service having problems, and hovering your cursor over the status icon (the ellipsis or “Ready” icon):
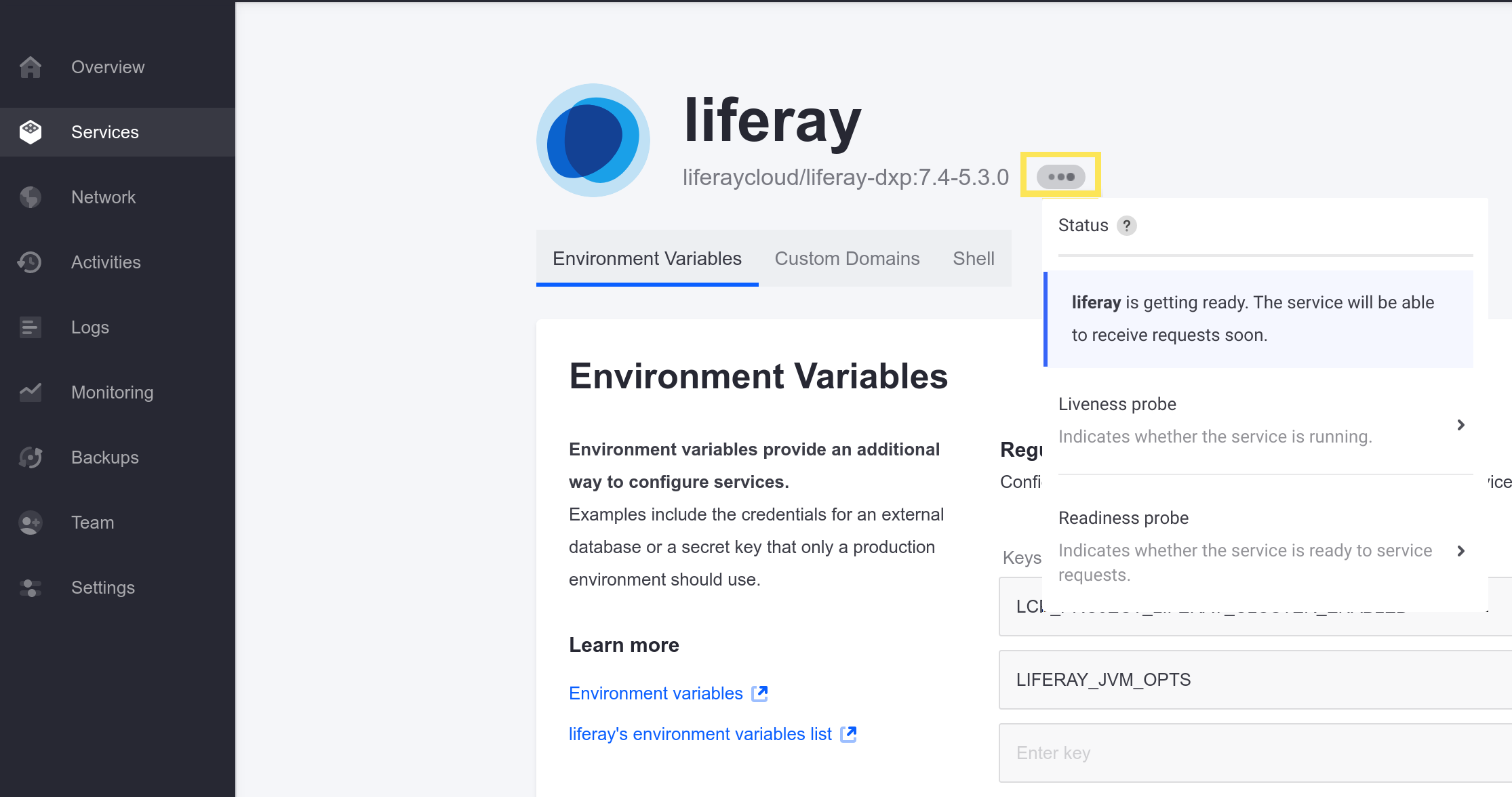
Click on the probe in question to see its configuration:
timeoutSeconds: 10
httpGet: path: /c/portal/layout
port: 8080
initialDelaySeconds: 120
periodSeconds: 15
failureThreshold: 3
successThreshold: 3
If the probe configuration values(such as the path or port values) are incorrect for your environment, then adjust them to the expected values in the service’s LCP.json file, in your project repository. Find this file in the directory corresponding to the service (e.g., liferay/), and then deploy the changes to your testing environment.
If your service’s LCP.json file does not already have the probe configurations, then you can copy the configurations shown in the console and convert them to JSON format while applying your changes. For example, readiness and liveness probe configurations for the liferay service may look like:
{
"readinessProbe": {
"httpGet": {
"path": "/c/portal/layout",
"port": 8080
},
"initialDelaySeconds": 120,
"periodSeconds": 15,
"timeoutSeconds": 10,
"failureThreshold": 3,
"successThreshold": 3
},
"livenessProbe": {
"tcpSocket": {
"port": 8080
},
"initialDelaySeconds": 300,
"periodSeconds": 60,
"timeoutSeconds": 10,
"failureThreshold": 3,
"successThreshold": 1
}
}
The default probe configurations should work for most environments. If you have not changed the probe configurations at all, then the issue is likely not a matter of incorrect configuration.
Review Service Logs for Startup Errors
If your probe configurations are correct, then the probes failing may be a sign of a problem with the service itself.
Check the logs to look for any error messages that may indicate a failed startup. If you can identify an error or problem in the startup logs, then this may be what is causing one or more probes to fail, which would trigger a service restart.
For the Liferay service, look for this message to signal the first logs after a restart: [LIFERAY] To SSH into this container, run: "docker exec -it liferay-<node-id> /bin/bash".
Contact Support if you need assistance in handling Liferay startup errors.
Adjust Probe Configurations
If there are no obvious errors or problems in the startup logs for your service causing the probe failures, but the service is still restarting, then an adjustment to the probe configurations may be necessary.
Services that take a long time to start up can lead to the liveness probe timing out early, triggering a service restart. This is likely the case if the normal startup logs have not all appeared by the time the probes fail and trigger a restart. This is not as likely to be the case if it is the readiness probe failing after the service has already fully started.
If this is happening for your service, then try one of the following:
- Increase the
initialDelaySecondsvalue for the probes to wait longer before checking the service. - Increase the
failureThresholdto force the probes to make more attempts before triggering a service restart. - Increase the
timeoutSecondsvalue to reduce the chance of a probe failure, if responses from the service are slow.
Increase one or more of these values in the probe configurations (in the service’s LCP.json file) and deploy the changes as appropriate for your service if slowness is causing service restarts. However, avoid setting these values too arbitrarily high, because the changes will apply to the probes for every service restart in the future.
See Using and Configuring Probes for more information.
Contact Cloud Support
If liveness or readiness probe failures are not causing the service restarts, or if these strategies have not helped to resolve them, then please contact Liferay Cloud Support for further assistance.
Accessing a Site with a CDN Causes JavaScript Errors
Some third-party CDNs can sort query strings (such as Cloudflare). Sorting can cause problems (like failing to load jQuery) when accessing a site using a custom domain name. This can result in JavaScript console errors like this:
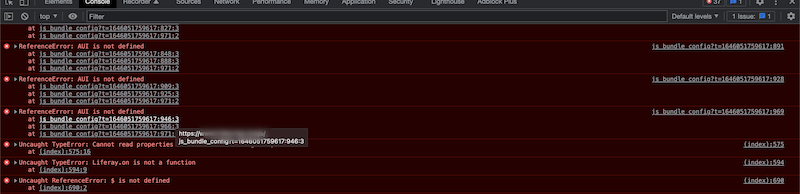
If this happens, your site may not load properly. To fix these errors, disable your CDN’s query string sorting. See your CDN’s documentation for exact steps (e.g., Cloudflare’s Query String Sort documentation).
If errors persist with sorting disabled, contact Liferay Cloud Support for assistance.